Bitmap.Config.HARDWARE 介绍 最近在一些内存很低的机器上做应用内存优化,实际上除了排查内存泄漏外,其他常见的方法对快速降低内存占用不太明显。一个应用端的应用,特别是会加载很多图片的应用,大部分内存都用来加载Bitmap了,一张铺面全屏的图片,粗略算算会占用接近8MB的内存(1920x1080x4B),我们可以从减少Bitmap的内存占用入手降低native内存占用,常见的方法是将 inPreferredConfig 从 Bitmap.Config.AGRB8888 改成 Bitmap.Config.RGB565 ,这样能少一半的内存占用。Android 8.0 API Level 26 后还存在一种叫 Bitmap.Config.HARDWARE 的配置,它的介绍如下:
在这种配置下,Bitmap只存在 GPU内存 中,适用于只用于显示的Bitmap。那是不是这部分bitmap内存就不存在native堆中了呢?接下来我们通过实验验证,使用BitmapFactory加载显示一张宽高都是8000px的图片,如果以 AGRB8888 加载,会占用 8000x8000x4B 约等于 244MB 的内存空间,加载的代码如下:
1 2 3 4 5 6 7 8 9 10 11 BitmapFactory.Options options = new BitmapFactory.Options(); options.inScaled = false ; Bitmap bitmap = BitmapFactory.decodeResource(getResources(), R.drawable.large, options); imageview.setImageBitmap(bitmap);
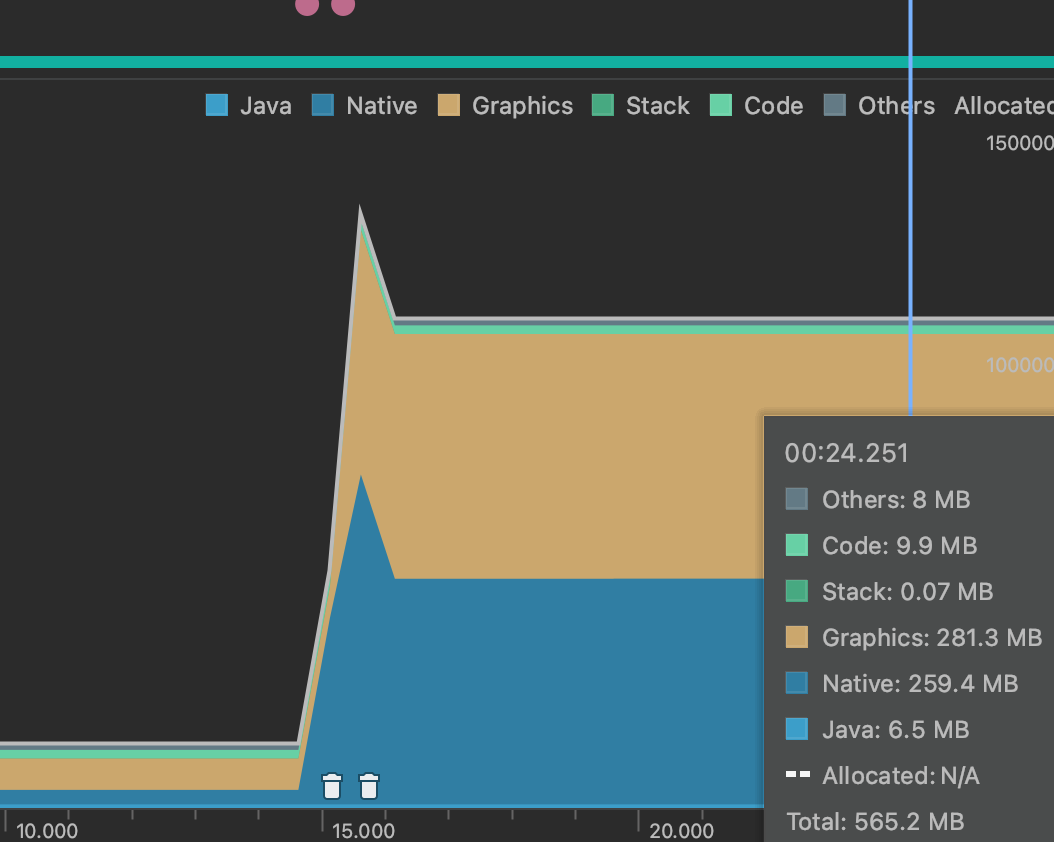
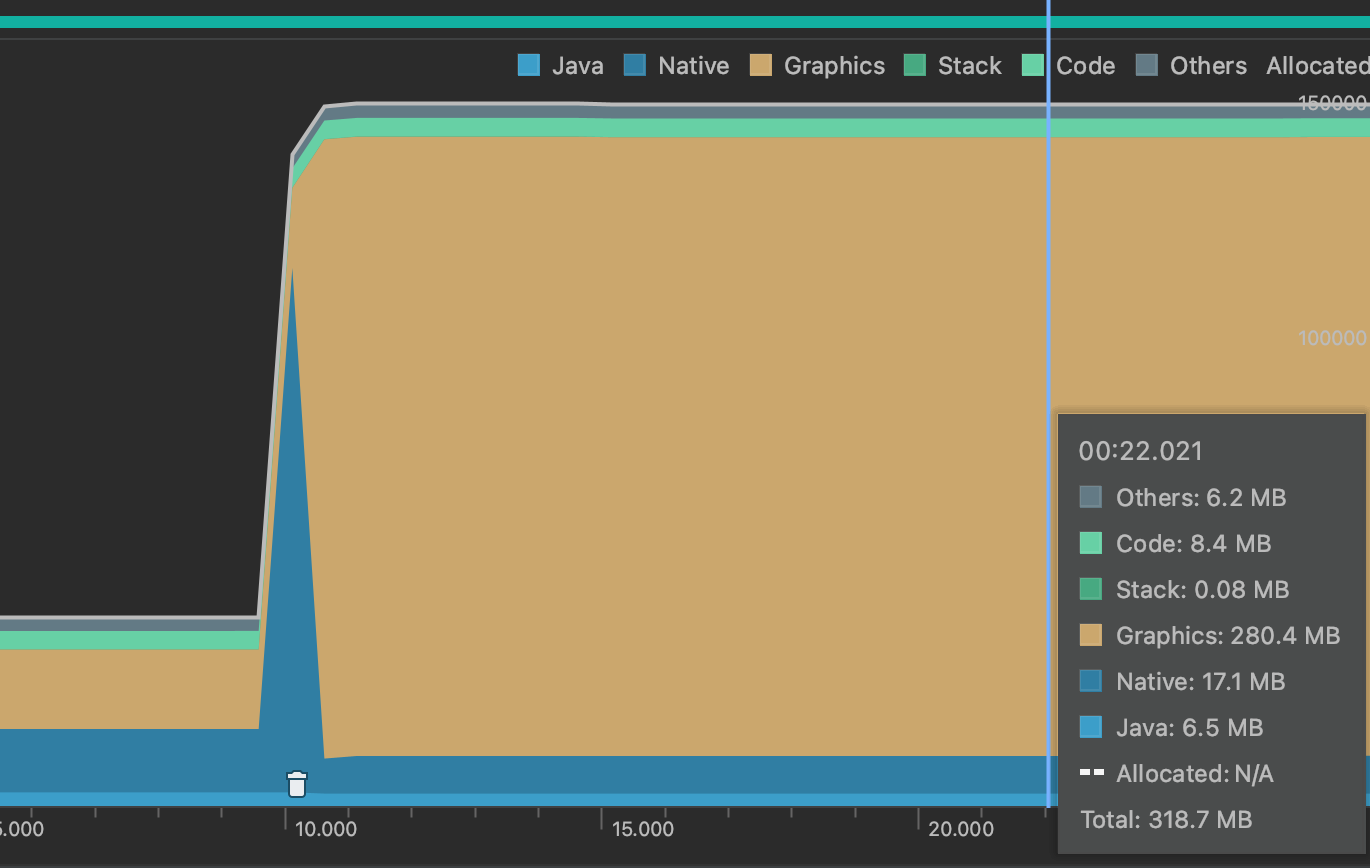
使用AGRB8888加载时profiler memory:
使用HARDWARE加载时profiler memory:AGRB8888 时,明显存在两部分大小相等的内存被分配,一部分在native中,对应客户端进程加载这张大图时分配的内存,而另一部分被统计在了 Graphics ,表示为了渲染这张图片和 GPU 共享的显示内存。而使用 HARDWARE 时,在开始加载时native内存会突然激增,之后内存被快速回收,推测是使用解码器解码图片时生成的真正的bitmap,这和使用什么样的 Bitmap.Config 没关系,无论怎么优化也需要先得到这张bitmap才行。之后将bitmap立马上传到GPU显存后立即释放了内存,所以最终会看到只是增大了共享GPU内存,而native内存回归了以前的水平。
所以通过实验证明了使用 HARDWARE 确实可以节约一部分加载图片的内存。
加载硬件位图的源码 以使用BitmapFactory为例:
1 2 3 4 -> frameworks/base/graphics/java/android/graphics/BitmapFactory.java decodeStream () -> frameworks/base/graphics/java/android/graphics/BitmapFactory.java nativeDecodeAsset () -> frameworks/base/libs/hwui/jni/BitmapFactory.cpp nativeDecodeAsset () -> frameworks/base/libs/hwui/jni/BitmapFactory.cpp doDecode ()
在 doDecode 中会调用解码器解码各种格式的图片文件,然后把它们转换成Android中Bitmap,我们这里是加载硬件位图,这个方法中会继续再将Bitmap内存上传到 GPU内存中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static jobject doDecode (JNIEnv* env, std::unique_ptr<SkStreamRewindable> stream, jobject padding, jobject options, jlong inBitmapHandle, jlong colorSpaceHandle) if (isHardware) { sk_sp<Bitmap> hardwareBitmap = Bitmap::allocateHardwareBitmap(outputBitmap); if (!hardwareBitmap.get()) { return nullObjectReturn("Failed to allocate a hardware bitmap" ); } return bitmap::createBitmap(env, hardwareBitmap.release(), bitmapCreateFlags, ninePatchChunk, ninePatchInsets, -1 ); }
allocateHardwareBitmap 的调用栈如下:
1 2 3 4 -> frameworks/base/libs/hwui/hwui/Bitmap.cpp allocateHardwareBitmap () -> frameworks/base/libs/hwui/HardwareBitmapUploader.cpp allocateHardwareBitmap (const SkBitmap& sourceBitmap) -> frameworks/base/libs/hwui/HardwareBitmapUploader.cpp uploadHardwareBitmap () -> frameworks/base/libs/hwui/HardwareBitmapUploader.cpp EGLUploader onUploadHardwareBitmap ()
最后会在 EGLUploader 这个实现类中正式上传纹理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 bool onUploadHardwareBitmap (const SkBitmap& bitmap, const FormatInfo& format, AHardwareBuffer* ahb) override ATRACE_CALL(); EGLDisplay display = getUploadEglDisplay(); LOG_ALWAYS_FATAL_IF(display == EGL_NO_DISPLAY, "Failed to get EGL_DEFAULT_DISPLAY! err=%s" , uirenderer::renderthread::EglManager::eglErrorString()); const EGLClientBuffer clientBuffer = eglGetNativeClientBufferANDROID(ahb); AutoEglImage autoImage (display, clientBuffer) ; if (autoImage.image == EGL_NO_IMAGE_KHR) { ALOGW("Could not create EGL image, err =%s" , uirenderer::renderthread::EglManager::eglErrorString()); return false ; } { ATRACE_FORMAT("CPU -> gralloc transfer (%dx%d)" , bitmap.width(), bitmap.height()); EGLSyncKHR fence = mUploadThread->queue().runSync([&]() -> EGLSyncKHR { AutoSkiaGlTexture glTexture; glEGLImageTargetTexture2DOES(GL_TEXTURE_2D, autoImage.image); if (GLUtils::dumpGLErrors()) { return EGL_NO_SYNC_KHR; } glTexSubImage2D(GL_TEXTURE_2D, 0 , 0 , 0 , bitmap.width(), bitmap.height(), format.format, format.type, bitmap.getPixels()); if (GLUtils::dumpGLErrors()) { return EGL_NO_SYNC_KHR; } EGLSyncKHR uploadFence = eglCreateSyncKHR(eglGetCurrentDisplay(), EGL_SYNC_FENCE_KHR, NULL); if (uploadFence == EGL_NO_SYNC_KHR) { ALOGW("Could not create sync fence %#x" , eglGetError()); }; glFlush(); GLUtils::dumpGLErrors(); return uploadFence; }); if (fence == EGL_NO_SYNC_KHR) { return false ; } EGLint waitStatus = eglClientWaitSyncKHR(display, fence, 0 , FENCE_TIMEOUT); ALOGE_IF(waitStatus != EGL_CONDITION_SATISFIED_KHR, "Failed to wait for the fence %#x" , eglGetError()); eglDestroySyncKHR(display, fence); } return true ; } renderthread::EglManager mEglManager; };
glTexSubImage2D 方法就是将纹理上传到与GPU共享的内存中去的方法。到这里,就认为Bitmap内存已经变成了GPU共享内存了,但还有很多问题,比如 Skbitmap的内存这时哪里去了?一直没找到释放内存的代码。我们滑动布局时,这个共享内存的Bitmap是怎么同步画布移动的?为什么会占用两个文件描述符?这些问题现在暂时没法理解,希望以后有机会。
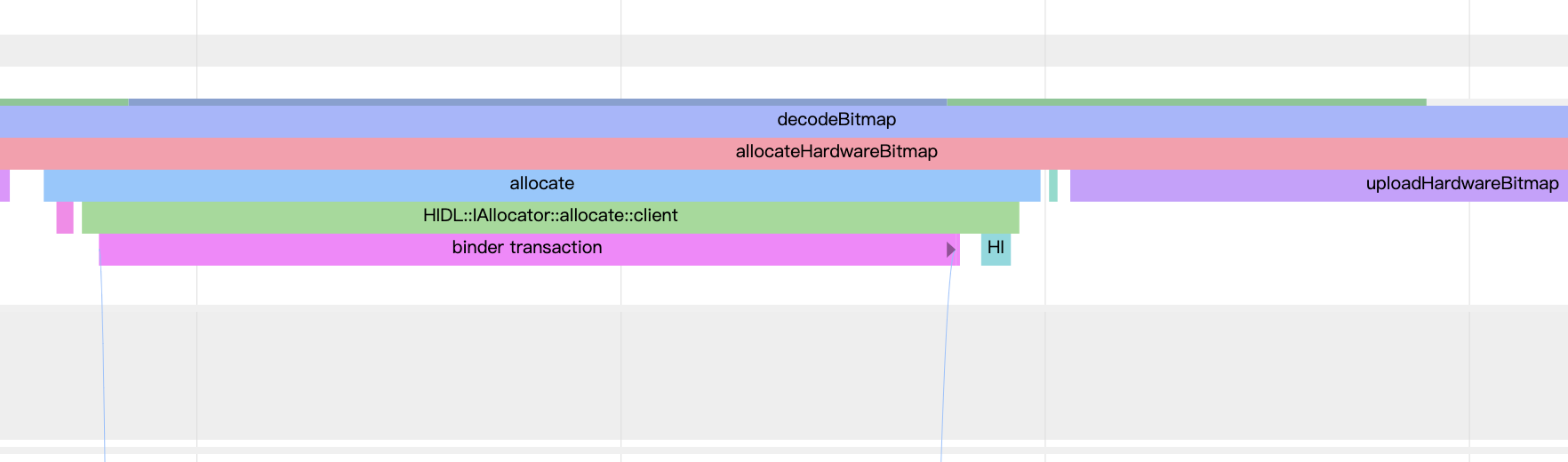
systrace日志 注意到上面 onUploadHardwareBitmap 有ATRACE日志,抓一段systrace验证下这个过程:
应用进程decode bitmap,可以看到这里直接发起了一次跨进程调用,目的是通知一个专门分配GPU内存的进程(这个应该是手机厂商实现的,不同的机器进程不一样)创建一块内存
分配GPU内存的进程,分配了一块内存
应用进程调用gl方法
Glide加载硬件位图 哈哈不出所料,我能遇到的问题 Glide 一定能帮我解决好了!实际上在Glide v4.1.0 版本中就加入了对硬件位图的支持,之后的迭代版本一直在优化这个功能。我们只需要加载图片时加入new RequestOption().set(Downsampler.ALLOW_HARDWARE_CONFIG, true); 它就可以自动帮我们加载硬件位图,并且它还帮我们判断了很多异常的情况,比如 1.文件描述符不足 2.EGL还没初始化 3.图片太小不值得😂 4.黑名单机型 等 ,一旦有一项不满足就不会使用硬件位图。Glide hardwarebitmaps介绍